RLDG: Robotic Generalist Policy Distillation via Reinforcement Learning


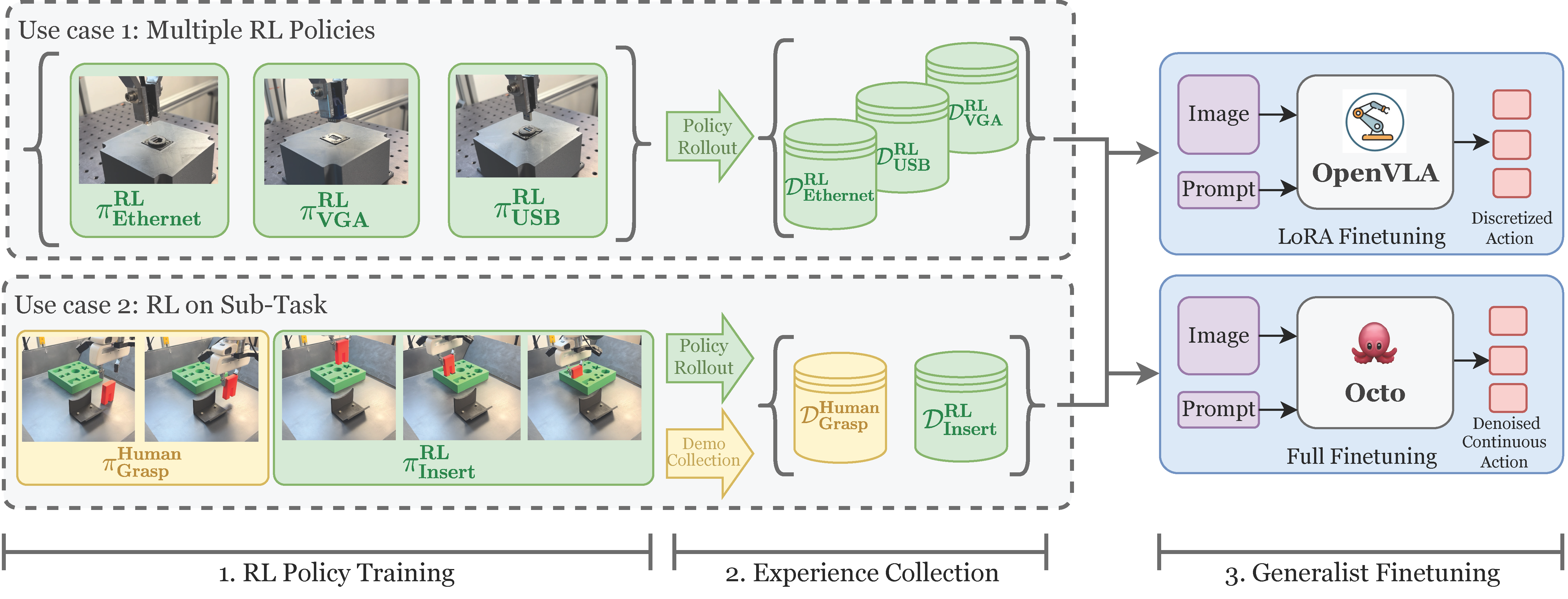
RLDG is a framework for distilling specialist RL policies into a generalist robot policy. Generalists trained this way demonstrate higher performance compared to conventional fine-tuning methods using human demonstrations, and stronger generalization capabilities over the RL policies that they are distilled from. It works by:
- Train specialist policies on narrowly scoped tasks using online Reinforcement Learning. This could look like training a separate policy for each type of connector in the insertion task. It can also be training on just the "bottleneck" portion of a long-horizon task, while leaving the rest for human demonstrations.
- Generate a dataset of expert trajectories by rolling out the specialist policies. The dataset can contain episodes with multiple variants of the task generated by different RL policies. It may also include expert human demonstrations for the "easy" portion of a long-horizon task.
- Use the high-quality dataset to fine-tune any generalist robot policy and see improved performance!